



Im ersten Schritt sollte wieder die Jira-Schnittstelle wie bereits beschrieben eingerichtet werden. Dies kann für einen oder mehrere Jira-Server geschehen.
Für den Jira-Migrator ist das zwar nicht unbedingt notwendig, aber wenn der Datenbestand automatisch aktuell gehalten werden soll, empfiehlt es sich.
Ohne das aktive Interface würden die Daten zwar in Can Do erzeugt, verblieben aber auf dem Stand zum Zeitpunkt der Migration.
Im zweiten Schritt wird die App Jira-Migrator ausgeführt. Dies geschieht im Namen des aktuellen Can Do-Anwenders; man ist also nicht gezwungen, wirklich das gesamte Jira-System zu übernehmen, sondern prinzipiell nur Daten, die für diesen Anwender zugänglich sind.
Der Jira-Migrator greift nun auf den Datenbestand von Jira zu und analysiert zuerst alle vorhandenen Boards und zeigt diese an.
 Die Boards werden gelesen und analysiert
Die Boards werden gelesen und analysiert
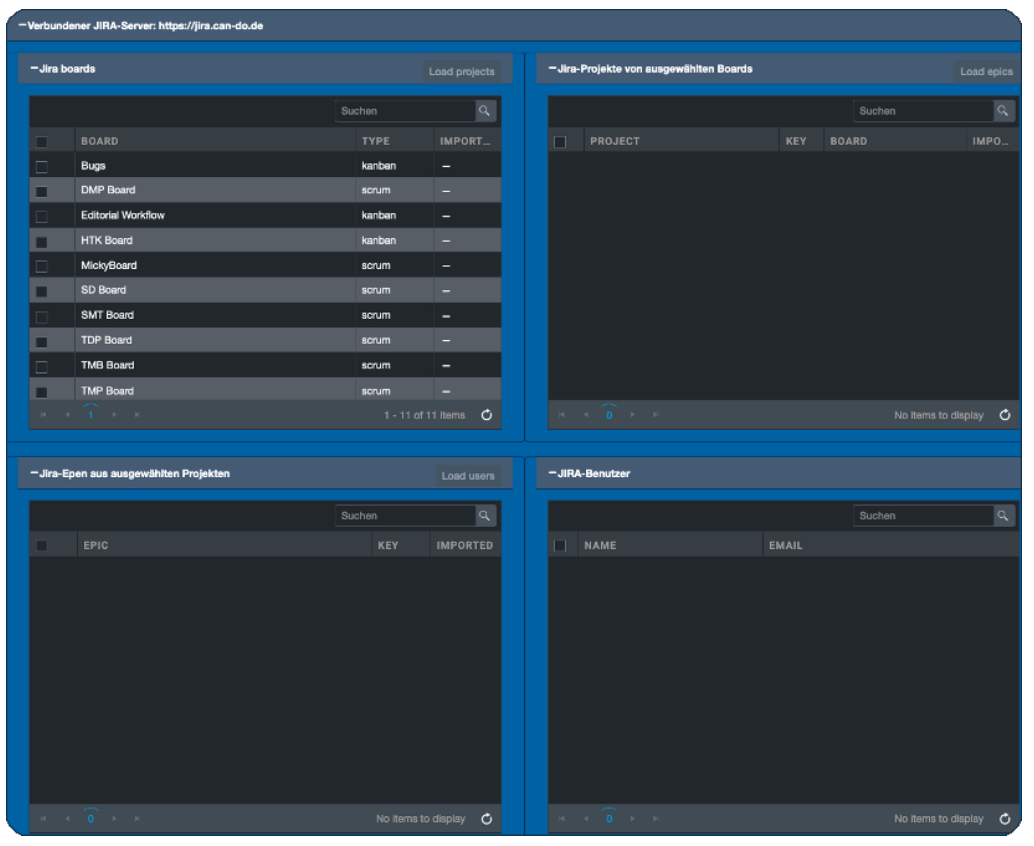 Die gelesenen Boards werden links oben mit ihrem Planungstypus dargestellt
Die gelesenen Boards werden links oben mit ihrem Planungstypus dargestellt
Der Anwender kann eines, mehrere oder alle Boards auswählen.
Das System beginnt alle Projekte, die in dem Board sind, zu analysieren. Da Projekte in Jira in mehreren Boards gleichzeitig vorkommen können, werden diese auf Eindeutigkeit geprüft und nur einmal dargestellt und später auch nur einmal erzeugt.
 Alle Projekte der selektieren Boards werden gelesen und analysiert
Alle Projekte der selektieren Boards werden gelesen und analysiert
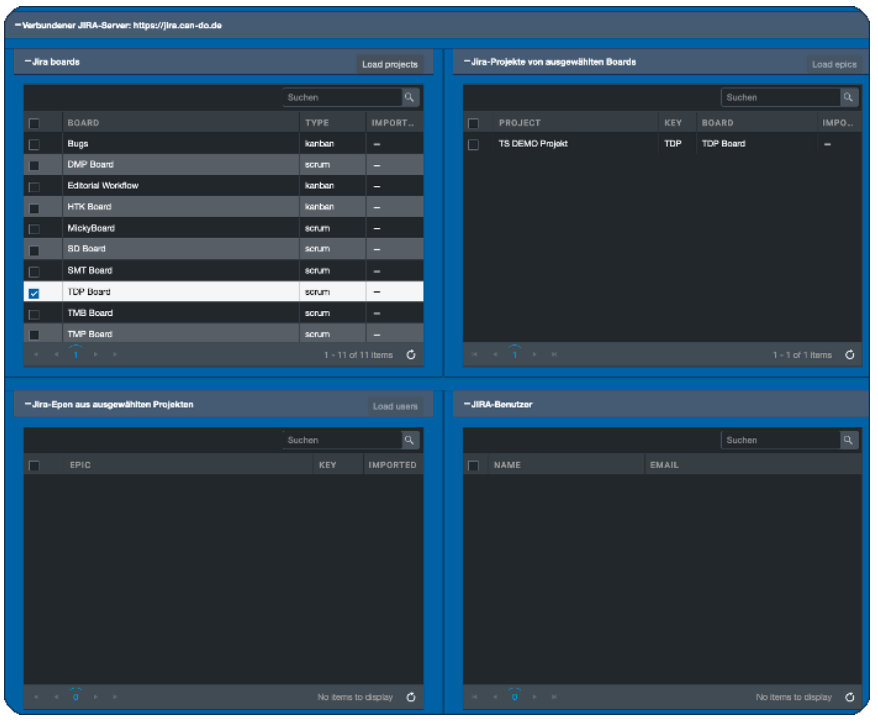 Die Projekte der selektierten Boards werden angezeigt
Die Projekte der selektierten Boards werden angezeigt
Das Prinzip ist also immer gleich: als Nächstes werden nun eines oder mehrere Projekte ausgewählt und die Epics werden gelesen, analysiert und angezeigt.
 Die Epics der selektierten Projekte werden gelesen und analysiert
Die Epics der selektierten Projekte werden gelesen und analysiert
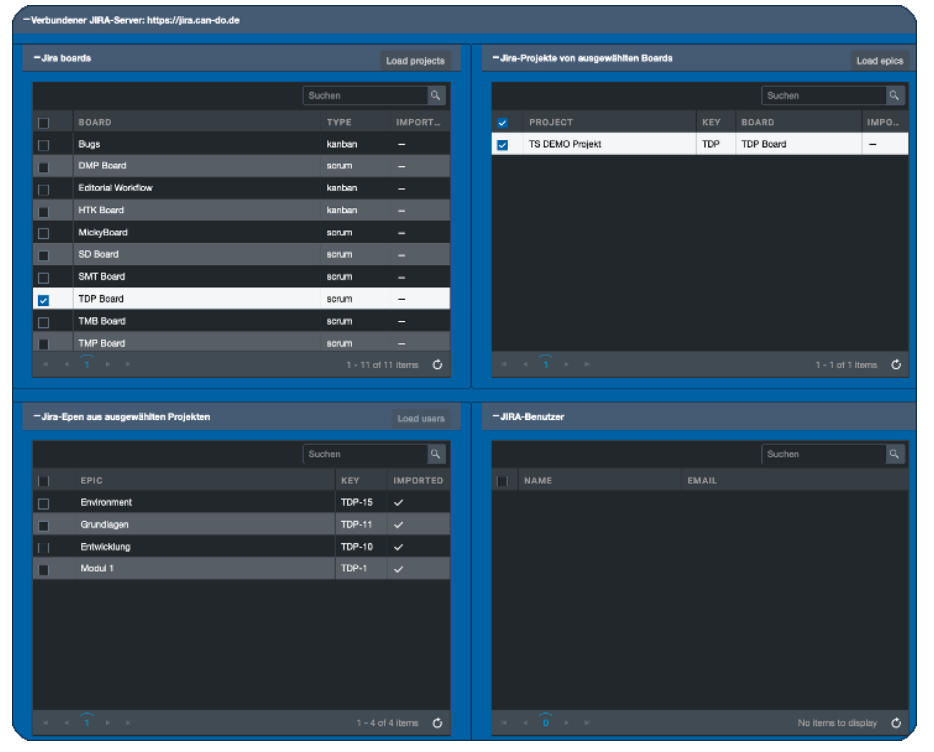 Alle Epics aller selektierten Projekte
Alle Epics aller selektierten Projekte
Nun kämen eigentlich die Storys auf der nächsten Ebene. Diese müssen nicht dargestellt werden, da das Can Do-Jira-Interface die Synchronisierung automatisch übernimmt.
Der letzte Schritt ist die Analyse der Benutzer, die in Jira existieren, aber in Can Do noch fehlen. Dabei werden nicht alle Jira-Anwender erzeugt. Es werden nur Ressourcen aus Jira erzeugt, die in Can Do noch nicht vorhanden sind und mindestens auf einer Jira Story oder Unteraufgabe eingesetzt wurden. Dadurch wird der Fall vermieden, dass ein Anwender gleichzeitig in zwei Jira-Servern existiert, aber natürlich in Can Do nicht doppelt angelegt werden soll.
Außerdem sollen nur Ressourcen in Can Do vorhanden sein, die planerisch eine Rolle spielen. Und das ist nur gegeben, wenn sie auch auf Storys geplant waren oder sind.
 Die Jira-User werden analysiert
Die Jira-User werden analysiert
Der Migrator muss jede Story analysieren. Da dies gerade bei größeren Unternehmen sehr viele sein können und der Jira-Server nicht durch mehrfache Zugriffe überlastet werden soll, kann das etwas dauern.
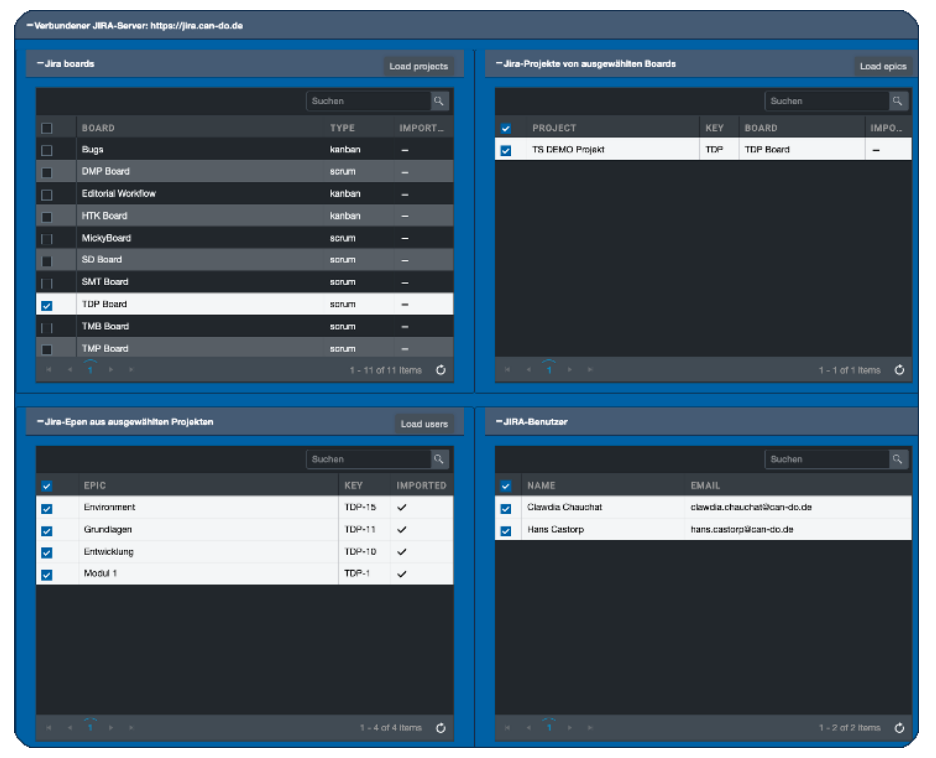 Alle relevanten User, die in Can Do erzeugt werden sollen
Alle relevanten User, die in Can Do erzeugt werden sollen
Der Anwender des Migrators kann nun die Anwender selektieren, die er auch in Can Do haben möchte. Lässt er Personen weg, werden diese nicht angelegt, aber auch keine Zuweisung auf Storys vorgenommen. Diese Personen existieren dann in Can Do nicht und haben auch kein Kapazitätsmodell.
Jetzt kann der Migrator gestartet werden und er kann dann die entsprechenden Objekte in Can Do erzeugen.
Begonnen wird mit den Boards. Für jedes (selektierte) Board wird in Can Do ein Portfolio angelegt.
Danach folgen die Projekte. Die Projekte werden dann den entsprechenden Portfolios zugewiesen. Da ein Projekt in Can Do in mehreren Portfolios vorkommen kann, genau wie in Jira ein Projekt in mehreren Boards sein kann, wird das 1:1 umgesetzt.
In den Projekten werden die Epics automatisch als Phasen angelegt und mit dem passenden Epic in Jira verbunden.
Parallel dazu werden die Ressourcen angelegt und als User gleich mit eingerichtet.
Die Schnittstelle beginnt nun mit dem Synchronisieren aller Storys unter den Epics, die in einem Sprint sind oder waren. Dies läuft asynchron im Hintergrund ab. Ein Can Do-Anwender kann ein importiertes Projekt jederzeit öffnen und beobachten, wie die Pakete erzeugt werden.
Boards, Projekte und Epics haben in Jira keine Termine. In Can Do würde das bedeuten, dass die Planungsobjekte alle nur einen Tag lang sind.
Sobald alle Pakete für eine Phase erzeugt wurden, bzw. alle Phasen für ein Projekt und alle Projekte für ein Portfolio, wird ein weiterer Algorithmus gestartet. Dieser analysiert die Termine der Pakete und passt alle Termine der darüber liegenden Elemente wie Phasen, Projekte und Portfolios automatisch an.
Die Migration kann, je nach Datenmenge, mehrere Stunden dauern. Das Can DoSystem könnte zwar mehrere parallele Kanäle zum Jira-Server einrichten und so deutlich schneller arbeiten. Da aber der Jira-Server im produktiven Betrieb ist, besteht die Gefahr, dass sich dieser verlangsamt. Das wird so verhindert.
Ein existierender Can Do-Server mit Hunderten oder Tausenden Anwendern, bei dem eine Migration läuft, hat keinerlei Einschränkungen oder Laufzeitverluste während dieses Vorgangs. Der Can Do-Server ist viel zu leistungsstark, als dass damit das System langsamer werden würde.
Es können auch mehrere Jira-Server in einen Can Do-Server migriert werden. Dies kann parallel erfolgen, d.h. es werden auf der Can Do-Seite einfach mehrere MigratorApps im Browser gestartet, für jeden Jira-Server ein Migrator.
Auch wenn die Migration lange dauert, sorgt das Can Do-Jira-Interface dafür, dass während dieser Zeit Änderungen im Jira-System sofort in Can Do nachgezogen werden. Die Nutzung von Jira muss also während der Migration nicht eingestellt oder eingeschränkt werden. Die Migration kann daher im laufenden Betrieb beider Systeme problemlos erfolgen.
Das Can Do-System „merkt“ sich, welche Portfolios, Projekte und Phasen über den Migrator erzeugt wurden. Im Migrator ist dann ein Haken für diese Objekte sichtbar.
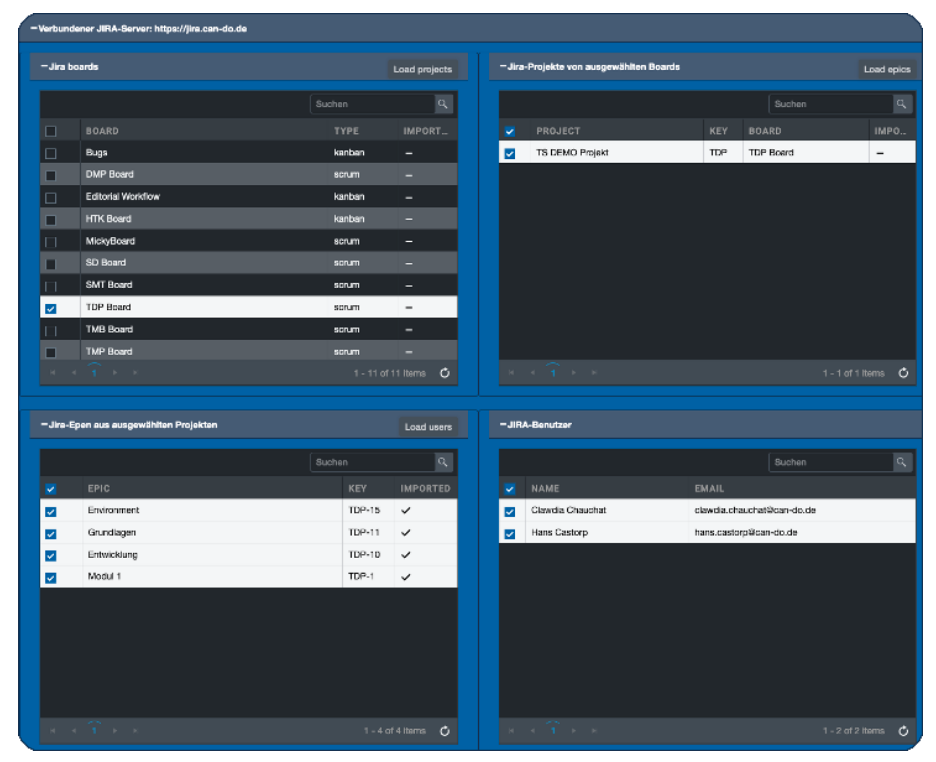 Die Epics unten links wurden bereits importiert
Die Epics unten links wurden bereits importiert
Daher gibt es auch die Möglichkeit, die Migration rückgängig zu machen (Unmigrate). Es wird nach dem gleichen Verfahren gearbeitet. Der Anwender wählt importierte Elemente in der App aus und aktiviert die Funktion „Unmigrate“. Die Elemente werden dann in Can Do wieder gelöscht.
Der Can Do-Jira-Migrator ist ein faszinierendes Stück Software. Es ist beeindruckend zu sehen, wie die Jira-Daten in Can Do aufgebaut werden und alle Möglichkeiten der Can Do Software sofort zur Verfügung stehen.

